
Цей пост є Частиною 4 з чотиричастинної серії. Обов’язково переглянь інші пости в серії для глибшого занурення у наш генератор бізнес-планів, що працює на штучному інтелекті.
Частина 1: Як Ми Створили Генератор Бізнес-Планів на Базі ШІ, Використовуючи LangGraph & LangChain
Частина 2: Як Ми Оптимізували Генерацію Бізнес-Планів на ШІ: Швидкість Проти Якості Компромісів
Частина 3: Як Ми Створили 273 Юніт-Тести За 3 Дні Без Написання Жодного Рядка Коду
Частина 4: Рамки Оцінювання ШІ — Як Ми Створили Систему для Оцінювання та Покращення Бізнес-Планів, Створених ШІ
Вступ: Виклики Оцінювання Бізнес-Планів з ШІ
Об’єктивне оцінювання контенту, створеного штучним інтелектом, є складним. На відміну від структурованих результатів з чіткими правильними або неправильними відповідями, бізнес-плани передбачають стратегічне мислення, оцінку можливостей та зв’язність, що робить оцінювання високо суб’єктивним.
Це порушило ключові виклики:
- Як ми оцінюємо “хороший” проти “поганого” змісту бізнес-плану?
- Як ми можемо забезпечити, щоб ШІ з часом самовдосконалювалася?
- Як нам зробити оцінювання послідовним і неупередженим?
Для вирішення цього ми розробили структурований оцінювальний фреймворк який дозволяє нам оцінювати, вдосконалювати та покращувати бізнес-плани, створені ШІ. Наш підхід поєднував декілька оцінювальних фреймворків, кожен з яких був адаптований до різних розділів плану, забезпечуючи точність та стратегічну глибину.
Важливо зазначити, що ця детальна система оцінювання була частиною нашої первісної реалізації, де кожен розділ пройшов сувору оцінку та ітерації. Однак, через обмеження продуктивності, ми спростили процес оцінювання у MVP, щоб надати пріоритет швидкості генерації. Цей компроміс допоміг нам швидше розгортати, при цьому зберігаючи рамки оцінювання як частину тривалих досліджень для майбутніх вдосконалень.
Недавні дослідження в галузі оцінювання на базі LLM підтвердили ефективність структурованого оцінювання ШІ. Дослідження, такі як Prometheus 2: Відкрита модель мови, спеціалізована на оцінюванні інших мовних моделей (2024) та фреймворк Evals від OpenAI показали, що LLM можуть бути надійними оцінювачами, коли їх керують структурованими критеріями оцінювання.
Розробка Фреймворку Оцінювання
Ми надихнулися системами оцінювання вчителів і застосували це до бізнес-планів, створених за допомогою ШІ. Це призвело до створення кількох оцінювальних Framework, кожен з яких адаптований до різних типів розділів.
Оцінювальні Рамки За Типами Розділів
Замість використання методу оцінювання один-на-всіх, ми розробили індивідуальні критерії оцінки залежно від типу контенту, що оцінюється:
Стратегічне планування та бізнес-модель
- Оцінено за ясністю, відповідністю SMART-цілям та можливістю реалізації.
- Вимагається чіткий план дій та структуроване встановлення цілей.
Дослідження ринку та конкурентний аналіз
- Зосереджені на глибині досліджень, відмінностях та підтвердженні даних у реальному світі.
- Відповіді ШІ оцінювалися за критеріями реалістичності ринку та конкурентного позиціонування.
Фінансове планування та прогнозування
- Оцінено фінансові припущення, моделювання доходів та розподіл витрат.
- Результати ШІ мали бути кількісно визначеними, внутрішньо узгодженими та розумними.
Операційна та Виконавча Стратегія
- Оцінено за критеріями можливості, мінімізації ризиків та плану реалізації.
- Необхідна чітка структура команди та розподіл ресурсів.
Стратегія Маркетингу та Продажів
- Оцінено за узгодженістю з цільовою аудиторією, потенціалом конверсії та послідовністю брендингу.
- Маркетингові плани, створені за допомогою ШІ, повинні бути конкретними та заснованими на даних.
Кожен фреймворк призначає вагу різним оціночним критеріям, забезпечуючи, що критичні аспекти (наприклад, фінансова стійкість) впливають на загальний бал більше, ніж менш критичні. Це узгоджується з останніми дослідженнями з Prometheus 2: Відкрите джерело мовної моделі, спеціалізованої на оцінці інших мовних моделей, які підкреслюють необхідність деталізованих оціночних бенчмарків з використанням LLMs.
Механізм Оцінювання Балів
Кожен розділ оцінювався від 1 до 5, згідно з критеріями:

Ітеративне Вдосконалення з ШІ
Щоб дати змогу ШІ самовдосконалюватись, ми розробили багатоетапне зворотне зв’язування:
Крок 1: Генерація Чернетки
- ШІ генерує початковий проект на основі вхідних даних користувача.
- Розділи структуровані відповідно до попередньо визначених шаблонів.
Крок 2: Самооцінка ШІ
- ШІ переглядає свій власний вихід за допомогою специфічних для розділу оціночних критеріїв.
- Визначає області з відсутніми даними, нечіткими поясненнями або слабкою стратегічною відповідністю.
Крок 3: Самовдосконалення ШІ
- ШІ регенерує слабкі секції, забезпечуючи краще узгодження з критеріями оцінки.
- Якщо фінансові дані або аналіз ринку недостатні, ШІ коригує припущення та аргументацію.
Крок 4: Фінальна Оцінка
- ШІ проводить другий оціночний прохід для підтвердження власних покращень.
- Остаточна версія порівнюється з попередніми ітераціями для відстеження прогресу.
Цей ітеративний процес генерації → оцінки → вдосконалення відповідає передовим дослідженням, які показують, що оцінки на базі LLM покращуються з кожним проходженням.
Статистична Валідація: Чи Справді Це Спрацювало?
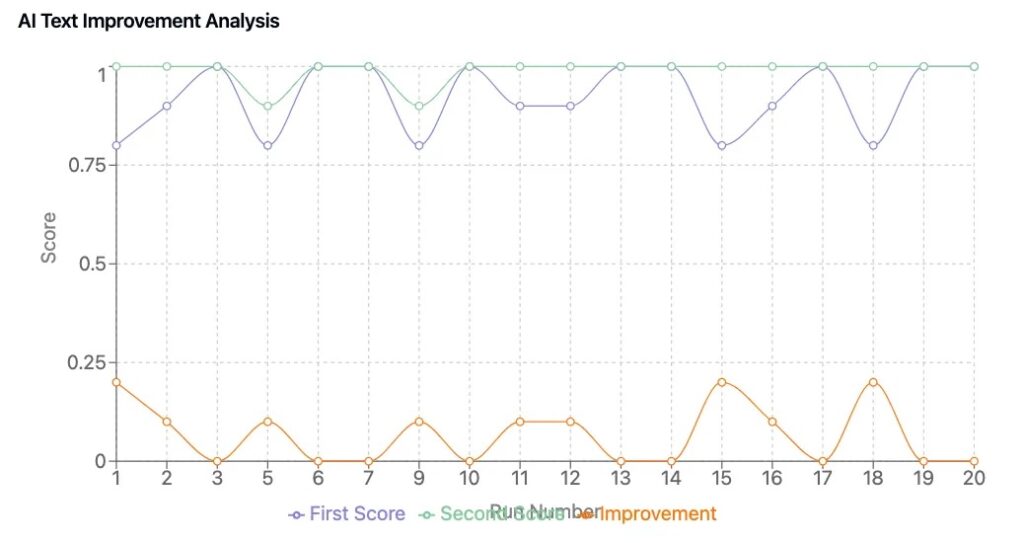
Щоб підтвердити, що наша структура призвела до помітних покращень, ми провели тестовий цикл з 50 планами, порівнюючи бізнес-плани, створені з ШІ, з та без петель самовдосконалення.
Основні Висновки
- Постійність Оцінювання: Контент, створений ШІ, оцінювався послідовно, зменшуючи випадкові коливання в якості плану.
- Вимірюване Покращення: Плани, які пройшли удосконалення за допомогою ШІ, покращились в середньому на 0.6 до 1.2 балів.
- Кращі Бізнес-Інсайти: Удосконалені версії мали краще стратегічне вирівнювання, чіткіші фінансові прогнози та більш переконливі повідомлення.
Ці висновки відображають тенденції, спостережені в дослідженні оцінювання LLM, де структуровані системи оцінювання і ітеративне оцінювання значно покращують згенерований ШІ контент.
Основні Висновки
1. ШІ може самовдосконалюватися за наявності структурованих критеріїв оцінки
- Добре визначена система оцінювання дозволяє ШІ визнавати та виправляти власні слабкі місця.
2. Кількісне Оцінювання Забезпечує Об’єктивну Валідацію Контенту
- Суб’єктивні оцінки були мінімізовані за допомогою стандартизованих оцінювальних таблиць.
3. Рамка оцінювання була розроблена для передових ітерацій ШІ, але MVP зосереджено на швидкості
- Спочаткова реалізація включала кілька циклів оцінювання на розділ.
- Через обмеження продуктивності ми спростили це в MVP але зберегли для майбутніх досліджень та вдосконалень.
4. Оцінювачі LLM — це Тенденція в Індустрії
- Нові моделі оцінювання ШІ (наприклад, Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, LLMs-as-Judges) покращують послідовність та зменшують упередженість. (arxiv.org)
- Галузь оцінювання ШІ розвивається в напрямку багаторівневих систем оцінювання, підтверджуючи підхід, який ми започаткували.
Спробуй Наш Бізнес-Пакет на Базі ШІ
Ми розробили та оптимізували наш генератор бізнес-планів на основі ШІ у DreamHost, забезпечивши рівень продуктивності та масштабованості для великих підприємств.
Клієнти DreamHost можуть клікнути тут, щоб розпочати та дослідити наш генератор бізнес-планів з ШІ та інші інструменти ШІ.
Цей пост є Частиною 4 з чотиричасткової серії. Обов’язково переглянь інші пости в серії, щоб глибше зануритись у наш генератор бізнес-планів з ШІ.
Частина 1: Як ми створили генератор бізнес-планів з ШІ за допомогою LangGraph & LangChain
Частина 2: Як ми оптимізували генерацію бізнес-планів з ШІ: компроміси швидкості та якості
Частина 3: Як ми створили 273 модульних тестів за 3 дні без написання жодного рядка коду
Частина 4: Рамки оцінки ШІ — Як ми створили систему для оцінювання та поліпшення бізнес-планів, створених ШІ