
Ten post to Część 4 z serii czteroczęściowej. Koniecznie sprawdź pozostałe posty w serii, aby lepiej poznać nasz generator planów biznesowych oparty na SI.
Część 1: Jak zbudowaliśmy generator planów biznesowych oparty na SI, używając LangGraph & LangChain
Część 2: Jak zoptymalizowaliśmy generowanie planów biznesowych SI: kompromis między szybkością a jakością
Część 3: Jak stworzyliśmy 273 testy jednostkowe w 3 dni bez pisania ani jednej linii kodu
Część 4: Ramka oceny SI — Jak zbudowaliśmy system do oceny i poprawy planów biznesowych generowanych przez SI
Wstęp: Wyzwanie oceny planów biznesowych AI
Ocena treści generowanych przez SI obiektywnie jest skomplikowana. W przeciwieństwie do strukturalnych wyników z jasno określonymi poprawnymi lub błędnymi odpowiedziami, plany biznesowe wymagają strategicznego myślenia, oceny wykonalności i spójności, co czyni ocenę wysoce subiektywną.
To postawiło przed nami kluczowe wyzwania:
- Jak możemy określić „dobrą” vs. „złą” treść planu biznesowego?
- Jak możemy zapewnić, że SI będzie samodoskonalić się z czasem?
- Jak sprawić, by ocena była spójna i bezstronna?
Aby rozwiązać ten problem, opracowaliśmy ustrukturyzowane ramy oceniania, które pozwalają nam oceniać, iterować i doskonalić generowane przez SI plany biznesowe. Nasze podejście łączyło wiele ram oceniania, każde dostosowane do różnych sekcji planu, zapewniając zarówno dokładność, jak i strategiczną głębię.
Ważne jest, aby zauważyć, że ten szczegółowy system oceny był częścią naszej pierwotnej implementacji, gdzie każda sekcja przeszła rygorystyczną ocenę i iterację. Jednakże, ze względu na ograniczenia wydajności, my uproszciliśmy proces oceny w MVP aby priorytetowo traktować szybkość generowania. Ten kompromis pozwolił nam szybciej wdrożyć, zachowując jednocześnie ramy oceny jako część bieżących badań na rzecz przyszłych ulepszeń.
Najnowsze badania w zakresie Oceny opartej na modelach językowych LLM potwierdziły skuteczność strukturalnej oceny sztucznej inteligencji. Badania takie jak Prometheus 2: Otwarte oprogramowanie językowe specjalizujące się w ocenie innych modeli językowych (2024) i framework Evals od OpenAI wykazały, że LLM mogą być wiarygodnymi oceniającymi, gdy są kierowane przez strukturalne kryteria oceny.
Projektowanie Ramy Ocen
Zainspirowaliśmy się systemami oceniania nauczycieli i zastosowaliśmy to do AI-generowanych planów biznesowych. Doprowadziło to do stworzenia kilku ram oceny, każdej dostosowanej do różnych typów sekcji.
Ramki Ocen Według Typu Sekcji
Zamiast stosować jednolitą metodę oceniania, opracowaliśmy dostosowane kryteria oceny w zależności od rodzaju ocenianej treści:
Planowanie strategiczne & Model biznesowy
- Ocenione pod kątem jasności, zgodności z celami SMART oraz wykonalności.
- Wymagane jasne plany działań i strukturalne ustawianie celów.
Badania Rynku & Analiza Konkurencji
- Skupienie na głębokości badań, różnicowaniu i weryfikacji danych rzeczywistych.
- Odpowiedzi SI były oceniane pod kątem realizmu rynkowego i pozycjonowania konkurencyjnego.
Planowanie Finansowe & Prognozy
- Oceniono założenia finansowe, modelowanie przychodów i rozkład wydatków.
- Wyniki SI musiały być skwantyfikowane, spójne wewnętrznie i rozsądne.
Strategia Operacyjna i Wykonawcza
- Oceniane pod kątem wykonalności, minimalizacji ryzyka i mapy drogowej wykonania.
- Wymagana jasna struktura zespołu i alokacja zasobów.
Strategia Marketingu i Sprzedaży
- Oceniane pod kątem zgodności z grupą docelową, potencjału konwersji i spójności marki.
- Plany marketingowe generowane przez SI musiały być konkretne i oparte na danych.
Każdy framework przypisywał wagi różnym wymiarom oceny, zapewniając, że kluczowe obszary (np. zdolność finansowa) wpływały na ogólną ocenę bardziej niż mniej kluczowe. Jest to zgodne z najnowszymi wynikami z Prometheus 2: Otwarty Model Języka Specjalizujący się w Oceny Innych Modeli Językowych, które podkreślały potrzebę dokładnych benchmarków oceny wykorzystujących LLMs.
Mechanizm Oceny Wyników
Każda sekcja była oceniana od 1 do 5, zgodnie z rubryką:

Iteracyjne Doskonalenie Napędzane AI
Aby umożliwić SI samodoskonalenie, zaprojektowaliśmy wieloetapową pętlę sprzężenia zwrotnego:
Krok 1: Generowanie Szkicu
- SI generuje wstępny szkic na podstawie danych użytkownika.
- Sekcje są strukturyzowane zgodnie z wcześniej zdefiniowanymi szablonami.
Krok 2: Samoocena AI
- SI ocenia swoje wyniki w oparciu o specyficzne ramy oceny dla sekcji.
- Wskazuje obszary z brakującymi danymi, niejasnymi wyjaśnieniami lub słabym dopasowaniem strategicznym.
Krok 3: Samodoskonalenie AI
- SI regeneruje słabe sekcje, zapewniając lepsze dopasowanie do kryteriów oceny.
- Jeśli brakuje danych finansowych lub analizy rynku, SI dostosowuje założenia i rozumowanie.
Krok 4: Ostateczna Ocena
- SI przeprowadza drugie skanowanie w celu walidacji swoich ulepszeń.
- Ostateczna wersja jest porównywana z poprzednimi iteracjami w celu śledzenia postępów.
Ten iteracyjny generuj → oceniaj → ulepszaj proces jest zgodny z najnowszymi badaniami pokazującymi, że oceny oparte na LLM poprawiają się z każdą iteracją.
Weryfikacja Statystyczna: Czy To Naprawdę Działa?
Aby potwierdzić, że nasze framework doprowadziło do namacalnych ulepszeń, przeprowadziliśmy 50-planowy cykl testowy, porównując biznesplany wygenerowane przez SI z i bez pętli samodoskonalenia.
Kluczowe Wyniki
- Konsystencja Oceny: Treści wygenerowane przez SI oceniane są konsekwentnie, redukując przypadkowe fluktuacje jakości planów.
- Mierzalna Poprawa: Plany, które przeszły udoskonalenie napędzane przez SI poprawiły się średnio o 0,6 do 1,2 punktu.
- Lepsze Wnioski Biznesowe: Udoskonalone wersje miały mocniejsze dostosowanie strategiczne, klarowniejsze prognozy finansowe oraz bardziej przekonujące przekazy.
Te wyniki odzwierciedlają obserwowane trendy w badaniach oceny LLM, gdzie zastosowanie strukturyzowanych ram oceniania i iteracyjne punktowanie znacząco poprawiają treści generowane przez AI.
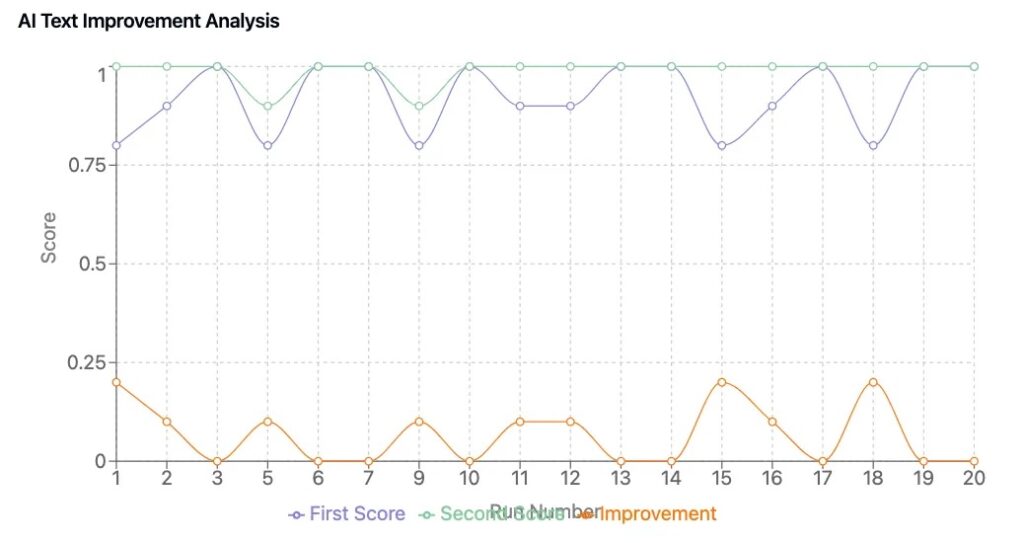
Kluczowe Wnioski
1. AI Może Samo Ulepszać Się, Gdy Zostanie Podana Struktura Kryteriów Oceny
- Dobrze zdefiniowany framework oceniania pozwala SI rozpoznać i poprawić własne słabości.
2. Ilościowe Punktowanie Zapewnia Obiektywną Walidację Treści
- Subiektywne oceny zostały zminimalizowane przez standaryzowane kryteria oceniania.
3. Opracowany Framework Oceny Został Zaplanowany dla Zaawansowanych Iteracji SI, ale MVP Skupiał Się Na Szybkości
- Oryginalna implementacja obejmowała wiele cykli oceny na sekcję.
- Ze względu na ograniczenia wydajności uproszczyliśmy to w MVP ale zachowaliśmy na przyszłe badania i doskonalenie.
4. Ewaluatorzy LLM To Trend na Całym Rynku
- Nowe modele oceny SI (np. Prometheus 2: Otwarty Model Języka Specjalizujący się w Oceny Innych Modeli Językowych, LLMs-as-Judges) poprawiają spójność i zmniejszają stronniczość. (arxiv.org)
- Dziedzina oceny SI ewoluuje w kierunku wielowarstwowych ram oceniania, potwierdzając podejście, które zainicjowaliśmy.
Wypróbuj Nasz Pakiet Biznesowy z Wykorzystaniem AI
Zbudowaliśmy i zoptymalizowaliśmy nasz generator planów biznesowych oparty na SI w DreamHost, zapewniając wydajność i skalowalność na poziomie przedsiębiorstwa.
Klienci DreamHost mogą kliknąć tutaj, aby rozpocząć i zapoznać się z naszym generatorem planów biznesowych zasilanym przez SI oraz innymi narzędziami SI.
Ten post jest Częścią 4 z 4-częściowej serii. Upewnij się, że sprawdziłeś też inne posty z tej serii, aby dokładniej zgłębić nasz generator planów biznesowych napędzany SI.
Część 1: Jak Zbudowaliśmy Generator Planów Biznesowych Napędzany SI, Używając LangGraph & LangChain
Część 2: Jak Zoptymalizowaliśmy Generowanie Planów Biznesowych SI: Kompromis Między Szybkością a Jakością
Część 3: Jak Stworzyliśmy 273 Testy Jednostkowe w 3 Dni Bez Pisania Ani Jednej Linii Kodu
Część 4: Ramka Ocen AI — Jak Zbudowaliśmy System do Oceny i Poprawy Generowanych przez SI Planów Biznesowych