
Dit bericht is Deel 4 van een vierdelige serie. Zorg dat je ook de andere berichten in de serie bekijkt voor een diepere duik in onze AI-gedreven bedrijfsplangenerator.
Deel 1: Hoe We Een AI-Gedreven Bedrijfsplangenerator Bouwden Met LangGraph & LangChain
Deel 2: Hoe We AI Bedrijfsplan Generatie Optimaliseerden: Snelheid vs. Kwaliteit Afwegingen
Deel 3: Hoe We 273 Unit Tests Creëerden in 3 Dagen Zonder Een Enkele Regel Code te Schrijven
Deel 4: AI Evaluatiekader — Hoe We Een Systeem Bouwden Om AI-Gegenereerde Bedrijfsplannen Te Beoordelen en Verbeteren
Introductie: De Uitdaging Van Het Evalueren Van AI Bedrijfsplannen
Het objectief evalueren van door AI gegenereerde inhoud is complex. In tegenstelling tot gestructureerde outputs met duidelijke juiste of onjuiste antwoorden, omvatten bedrijfsplannen strategisch denken, haalbaarheidsbeoordelingen en samenhang, wat de evaluatie zeer subjectief maakt.
Dit leidde tot belangrijke uitdagingen:
- Hoe kunnen we “goede” versus “slechte” zakelijke plannen inhoud kwantificeren?
- Hoe kunnen we ervoor zorgen dat AI in de loop van de tijd zelf verbetert?
- Hoe maken we de evaluatie consistent en onbevooroordeeld?
Om dit op te lossen, hebben we een gestructureerd beoordelingskader ontwikkeld dat ons in staat stelt om AI-gegenereerde bedrijfsplannen te evalueren, te itereren en te verbeteren. Onze aanpak combineerde meerdere evaluatiekaders, elk aangepast aan verschillende secties van het plan, waarbij zowel nauwkeurigheid als strategische diepgang wordt gegarandeerd.
Het is belangrijk om te vermelden dat dit gedetailleerde evaluatiesysteem onderdeel was van onze oorspronkelijke implementatie, waarbij elke sectie een grondige beoordeling en iteratie onderging. Echter, vanwege prestatiebeperkingen, hebben we het evaluatieproces in de MVP vereenvoudigd om de snelheid van generatie te prioriteren. Deze afweging hielp ons sneller te implementeren terwijl we het evaluatiekader als onderdeel van voortdurend onderzoek voor toekomstige verbeteringen behielden.
Recent onderzoek in LLM-gebaseerde evaluatie heeft de effectiviteit van gestructureerde AI-evaluatie bevestigd. Studies zoals Prometheus 2: Een Open Source Taalmodel Gespecialiseerd in het Evalueren van Andere Taalmodellen (2024) en OpenAI’s Evals framework hebben aangetoond dat LLM’s betrouwbare beoordelaars kunnen zijn wanneer ze worden geleid door gestructureerde scoringscriteria.
Het Ontwerpen Van Het Evaluatiekader
We hebben inspiratie opgedaan uit beoordelingssystemen van leraren en dit toegepast op door AI gegenereerde bedrijfsplannen. Dit leidde tot de creatie van meerdere evaluatiekaders, elk aangepast aan verschillende soorten secties.
Evaluatiekaders Per Sectietype
In plaats van een one-size-fits-all beoordelingsmethode te gebruiken, hebben we aangepaste beoordelingscriteria ontwikkeld afhankelijk van het type inhoud dat wordt geëvalueerd:
Strategische Planning & Bedrijfsmodel
- Beoordeeld op helderheid, SMART-doelafstemming en haalbaarheid.
- Vereist expliciete actieplannen en gestructureerde doelstellingen.
Marktonderzoek & Concurrentieanalyse
- Gericht op diepgang van onderzoek, differentiatie en validatie van echte wereld data.
- AI-reacties werden beoordeeld op marktrealisme en concurrentiepositie.
Financiële Planning & Prognoses
- Geëvalueerde financiële aannames, inkomstenmodellering en kostenverdeling.
- AI-output moest gekwantificeerd, intern consistent en redelijk zijn.
Operationele & Uitvoeringsstrategie
- Beoordeeld op haalbaarheid, risicobeperking en uitvoeringsroadmap.
- Vereist een duidelijke teamstructuur en middelentoewijzing.
Marketing- & Verkoopstrategie
- Beoordeeld op afstemming op doelgroep, conversiepotentieel en consistentie van branding.
- AI-gegenereerde marketingplannen moesten specifiek en op data gebaseerd zijn.
Elk framework heeft gewichten toegekend aan verschillende beoordelingsdimensies, waarbij ervoor is gezorgd dat kritische gebieden (bijv. financiële levensvatbaarheid) meer invloed hadden op de totale score dan minder kritische gebieden. Dit sluit aan bij recente bevindingen van Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models, die de noodzaak benadrukte van gedetailleerde evaluatiebenchmarks met gebruik van LLM’s.
Evaluatie Scoremechanisme
Elke sectie werd beoordeeld van 1 tot 5, volgens een beoordelingsschema:

AI-gestuurde Iteratieve Verbetering
Om AI in staat te stellen zichzelf te verbeteren, hebben we een meerstaps feedbacklus ontworpen:
Stap 1: Conceptgeneratie
- De AI genereert een eerste ontwerp op basis van gebruikersinvoer.
- Secties zijn gestructureerd volgens vooraf gedefinieerde sjablonen.
Stap 2: AI Zelfevaluatie
- De AI beoordeelt zijn eigen output tegen de specifieke evaluatiekaders.
- Identificeert gebieden met ontbrekende gegevens, vage uitleg, of zwakke strategische afstemming.
Stap 3: AI Zelfverbetering
- AI regenereert zwakke secties, wat zorgt voor beter afstemming met beoordelingscriteria.
- Als financiële gegevens of marktanalyse ontbreken, past AI aannames en redeneringen aan.
Stap 4: Definitieve Evaluatie
- De AI voert een tweede scoringsronde uit om zijn eigen verbeteringen te valideren.
- De uiteindelijke versie wordt vergeleken met voorgaande iteraties om de voortgang bij te houden.
Dit iteratieve genereren → evalueren → verbeteren proces sluit aan bij state-of-the-art onderzoek dat aantoont dat LLM-gebaseerde evaluaties verbeteren over meerdere stappen.
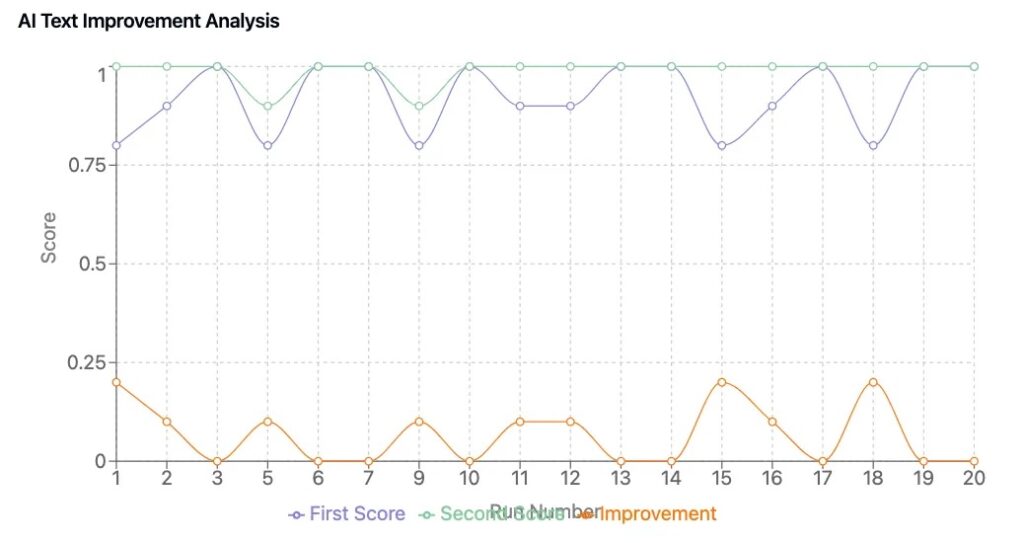
Statistische Validatie: Heeft Het Daadwerkelijk Gewerkt?
Om te bevestigen dat ons framework tot tastbare verbeteringen heeft geleid, hebben we een testcyclus van 50 plannen uitgevoerd, waarbij AI-gegenereerde bedrijfsplannen met en zonder zelfverbeteringslussen werden vergeleken.
Belangrijkste Bevindingen
- Scoringsconsistentie: AI-gegenereerde inhoud scoort consistent, waardoor willekeurige fluctuaties in de kwaliteit van het plan verminderen.
- Meetbare Verbetering: Plannen die AI-gestuurde verfijning ondergingen, verbeterden met gemiddeld 0,6 tot 1,2 punten.
- Betere Bedrijfsinzichten: Verfijnde versies hadden sterkere strategische afstemming, duidelijkere financiële prognoses en overtuigendere berichten.
Deze bevindingen weerspiegelen trends die zijn waargenomen in LLM-evaluatieonderzoek, waar gestructureerde beoordelingskaders en iteratieve scoring de door AI gegenereerde inhoud aanzienlijk verbeteren.
Belangrijkste Inzichten
1. AI Kan Zichzelf Verbeteren Als Het Gestandaardiseerde Evaluatiecriteria Krijgt
- Een goed gedefinieerd scoringskader stelt AI in staat om zijn eigen zwakke punten te herkennen en te corrigeren.
2. Kwantitatieve Beoordeling Zorgt Voor Objectieve Inhoudsvalidatie
- Subjectieve beoordelingen werden geminimaliseerd door gestandaardiseerde beoordelingsrichtlijnen.
3. Het Evaluatie Framework Was Ontworpen Voor Geavanceerde AI-Iteraties, Maar De MVP Richtte Zich Op Snelheid
- De oorspronkelijke implementatie bevatte meerdere evaluatiecycli per sectie.
- Vanwege prestatiebeperkingen hebben we dit in de MVP vereenvoudigd, maar behouden voor toekomstig onderzoek en verbetering.
4. LLM-Evaluatoren Zijn Een Industriebrede Trend
- Nieuwe AI evaluatiemodellen (bijv., Prometheus 2: Een Open Source Taalmodel Gespecialiseerd in het Evalueren van Andere Taalmodellen, LLMs-as-Judges) verbeteren de consistentie en verminderen de vooringenomenheid. (arxiv.org)
- Het veld van AI-evaluatie evolueert naar meerlagige scoringskaders, wat de aanpak die we pionierden valideert.
Probeer Onze AI-Gedreven Zakelijke Suite
We hebben onze door AI aangedreven bedrijfsplannengenerator bij DreamHost gebouwd en geoptimaliseerd, waarbij we ons hebben gericht op prestaties en schaalbaarheid op ondernemingsniveau.
DreamHost klanten kunnen hier klikken om te beginnen en onze AI-gedreven bedrijfsplanner en andere AI-tools te ontdekken.
Deze post is Deel 4 van een serie van vier delen. Zorg ervoor dat je de andere posts in de serie bekijkt voor een diepgaandere duik in onze AI-gedreven bedrijfsplannengenerator.
Deel 1: Hoe We Een AI-Gedreven Bedrijfsplannengenerator Hebben Gebouwd Met LangGraph & LangChain
Deel 2: Hoe We AI Bedrijfsplangeneratie Hebben Geoptimaliseerd: Snelheid versus Kwaliteitsafwegingen
Deel 3: Hoe We 273 Unit Tests Hebben Gecreëerd in 3 Dagen Zonder Een Enkele Regel Code Te Schrijven
Deel 4: AI Evaluatie Framework — Hoe We Een Systeem Hebben Gebouwd Om AI-GeGenereerde Bedrijfsplannen Te Beoordelen En Te Verbeteren